GenoPred Pipeline
The GenoPred pipeline is an easy-to-use and robust software pipeline, implementing leading methodology for polygenic scoring.
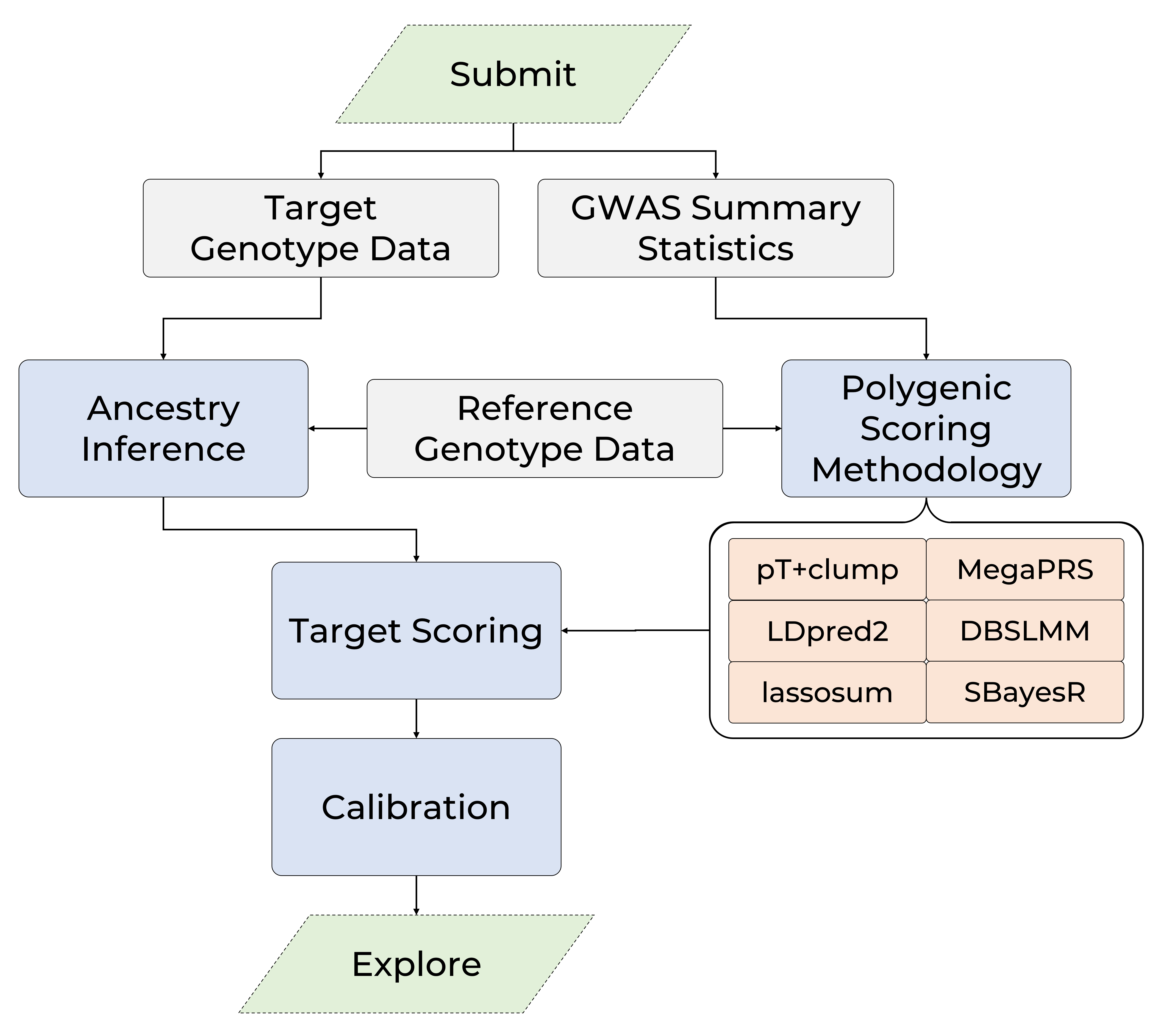
Polygenic scoring is an approach for calculating an individuals genetic risk or propensity for a given outcome, leveraging the results of large-scale genome-wide association studies (GWAS) using advanced machine learning methodology. Polygenic scores are used extensively in research and show great promise as a tool for enhancing personalised medicine.
The GenoPred pipeline facilitates the robust calculation of polygenic scores, taking commonly available input files in a range of formats, and returning polygenic scores and several other useful outputs (e.g. ancestry inference results, relatedness estimation, genetic principal components).
The pipeline uses the Snakemake workflow manager and conda environments providing scalable and reproducible analyses.
Promo Video
Publication
Check out our publication in Bioinformatics describing the pipeline: “The GenoPred Pipeline: A Comprehensive and Scalable Pipeline for Polygenic Scoring.” - Link
Any questions?
Please post questions as an issue on the GenoPred GitHub repo here.